Autopsie d'une dataviz [5.1] : gagner du temps sur QGis
Première partie d'une trilogie consacrée à un gros travail de cartographie réalisé pour Rue89Strasbourg. Au programme pour commencer : comment gagner un maximum de temps sur QGis.
Je me suis lancé il y a quelques semaines dans un projet assez costaud :
réaliser une cartographie électorale d'une énorme zone, en prenant comme références plus de 9 000 communes. Pour cela, je me suis servi de deux stocks de données gratuits :
- les limites communales répertoriées par les méticuleuses fourmis d'OpenStreetMap
- différents tableurs au format Excel glânés sur data.gouv.fr
Une fois le tri fait sur les communes que je souhaitais garder pour la future visualisation, je suis passé à l'étape QGis, du nom de cet excellent logiciel de cartographie distribué sous licence GNU.
Je m'attendais à devoir faire quelques modifications pour générer un .shp réutilisable, mais beaucoup de petites choses se sont accumulées et m'ont fait perdre un maximum de temps. J'en répertorie quelques-unes, en espérant que cela puisse resservir à quelqu'un.
Le pénible chemin des vers des syntaxes identiques
Ça a été le principal pépin au début : arriver à rassembler deux fichiers parlant de la même choses, mais pas forcément de la même façon...
Utiliser des fichiers en UTF-8
La première joyeuseté fut de voir des noms de communes avec accents ressembler à du yaourt à cause d'un mauvais codage. Pour se simplifier la vie, commencez par réenregistrer les fichiers non modifiés en UTF-8, ce sera déjà ça de pris.
Harmoniser les noms entre les fichiers
Avant d'espérer faire une carte interactive que chaque tracé communal d'OSM soit rattaché aux données de data.gouv. Sauf que les noms répertoriés chez OSM ne sont pas forcément écrits de la même façon que les noms du fichier fourni par l'administration.
Plusieurs raison à cela :
- certaines règles de nomenclature. Par exemple, la commune "Les Bouchoux" sur OSM sera noté "Bouchoux (Les)" dans le fichier de données, ou encore certains noms de commune à rallonge ne seront pas écrits avec des tirets dans l'un des fichiers. Et la correspondance ne se fera évidemment pas
- des erreurs de saisie ou des noms incomplets. Par exemple, le fichier OSM a noté la commune "Waldighofen", alors que la bonne orthographe est "Walidghoffen". Après avoir tout corrigé, je dois reconnaître que c'est bien le fichier OSM qui présentait le moins d'erreurs ou d'imprécision
Ces erreurs se détectent facilement lors de la jointure avec une base de données en .csv (je reviendrai sur la manip' plus loin) car les valeurs qui devraient s'afficher à côté des communes sont notés "NULL" dans la table d'attributs.
C'est donc que la correspondance ne s'est pas faite, et que les noms entre les fichiers sont différents.
Je n'ai pas d'autre méthode que de tout corriger, patiemment à la main, sur le fichier où se trouve l'erreur. Ce qui est évidemment fastidieux...
Chasser les doublons
Même à la fin, il restait forcément des doublons. Or, pour l'avoir constaté, QGis ne s'embête pas : il choisit au hasard l'un des éventails de valeurs d'une commune, et le duplique sur le doublon. On perd donc des informations, ce qui n'est évidemment pas l'objectif.
Du coup, en cas de doublons, il faut veiller à bien les différencier. Personnellement, j'ai ajouté dans mon fichier OSM et mon fichier administratif, le numéro de département entre parenthèses après la commune qui comptait le moins d'inscrits.
Quelques manip' bien utiles sur QGis
Nous avons maintenant deux fichiers qui parlent de la même chose de la même façon. C'est plutôt bien, mais il y a encore quelques trucs à peaufiner. Voici quelques astuces sur le logiciel QGis pour gagner encore un peu plus de temps.
Fusionner plusieurs shapefiles en un
Première étape : on a les tracés communaux de chaque département dans un .shp propre, et on aimerait tous les rassembler en un.
Il suffit d'ouvrir tous les .shp dans QGis, de les sélectionner dans la zone de gauche, puis d'aller dans > Vecteur > Outils de gestion de données > Fusionner les shapefiles en un seul.

Cliquez sur l'image pour l'agrandir
Une fois ceci fait, il ne reste plus qu'à choisir un dossier d'origine où sont rangés les .shp à fusionner, et un dossier de destination avec le nom du nouveau fichier.
En quelques secondes, le .shp nouveau est arrivé 🙂 !
Fusionner des entités en une seule
Le fichier d'OSM répertorie les limites communales de 2013. Seulement, il arrive que certaines de ces communes aient par le passé été fusionnées à d'autre, voire défusionnées.
Autrement dit, des données de 2009 peuvent avoir des communes en moins que celles de 2013 à cause de ces enjeux locaux.
Comment faire pour rassembler deux tracés voisins pour n'en faire plus qu'un seul ? Il faut d'abord sélectionner la couche .shp sur la zone de gauche, et la basculer en mode Edition (le bouton représentant un crayon).
Ensuite, il faut ouvrir la table d'attributs (> clic droit sur la couche .shp > Ouvrir la table d'attributs), sélectionner le premier tracé, puis le second en restant bien appuyé sur la touche Ctrl.
On peut vérifier que les deux entités ont bien été sélectionnées directement sur la carte. Elles doivent être colorées en jaune.
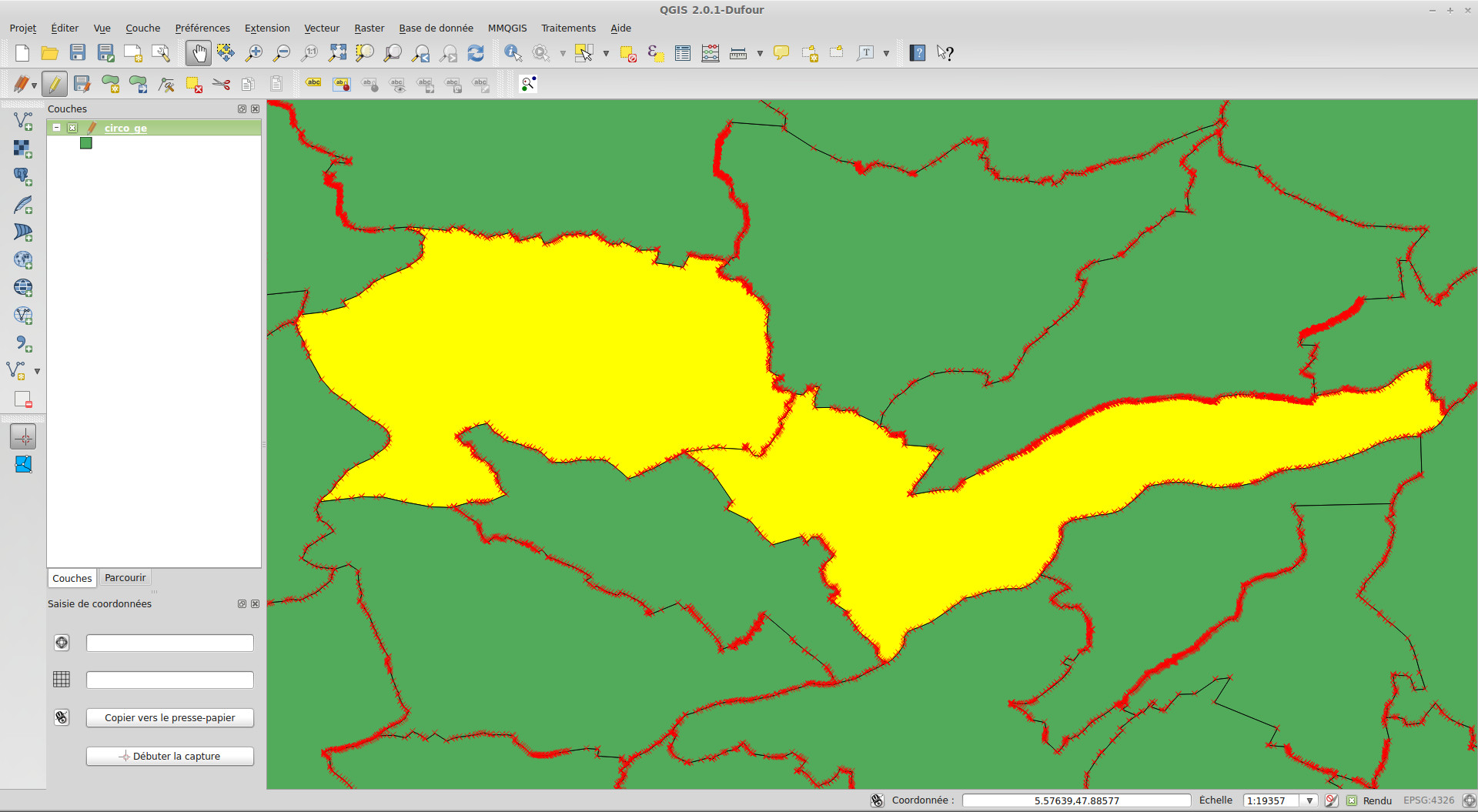
Cliquez sur l'image pour l'agrandir
On va alors dans > Editer > Fusionner les attributs des entités sélectionnées pour se retrouver sur les options suivantes.
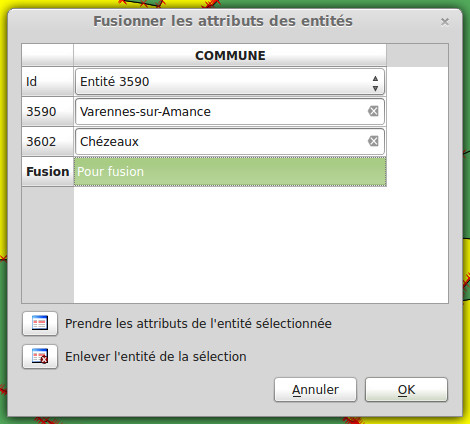
Cliquez sur l'image pour l'agrandir
Dans Fusion, il ne reste plus qu'à mettre le nom de la nouvelle entité, d'appuyer sur OK, et le tour est joué.
Cliquez sur l'image pour l'agrandir
Joindre une couche .shp à un fichier .csv
On s'approche tout doucement de notre .shp final, il ne reste plus qu'à placer les données dans le couche .shp.
Pour cette manipulation, on va utiliser un fichier .csv (bien sauvegardé en UTF-8 :-)) qui va inclure une colonne de commune dont chaque nom correspond précisément à chaque nom d'entité du fichier .shp.
On ouvre dans QGis le .shp et on fait glisser le .csv dans la même zone. Il ne reste plus qu'à double cliquer sur notre couche .shp, à aller dans l'onglet Jointure, à cliquer sur la croix verte et ensuite à choisir la bonne colonne de référence.
Voici l'illustration correspondante :
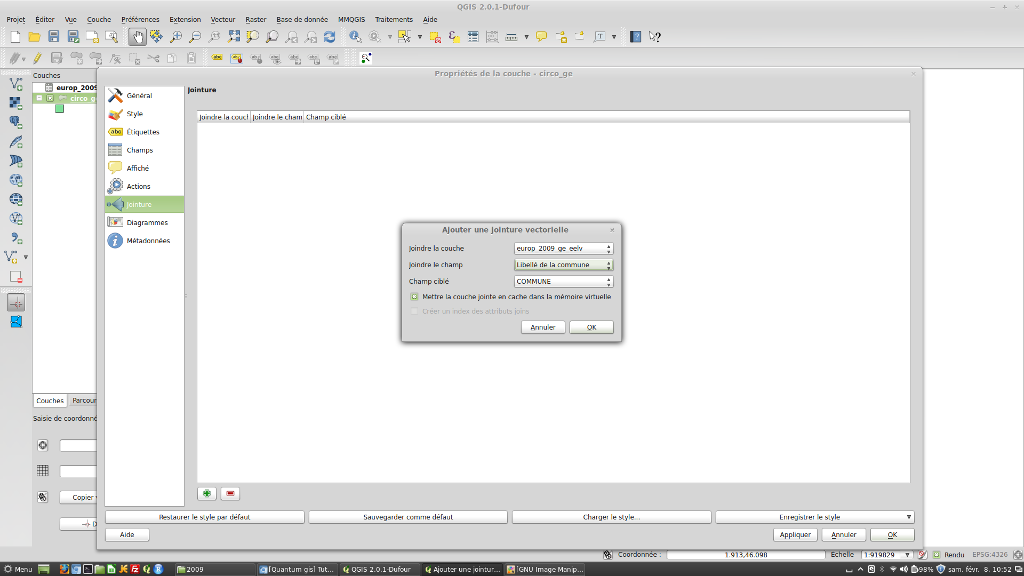
Cliquez sur l'image pour l'agrandir
Il ne reste plus qu'à vérifier dans notre table d'attributs que tout s'est bien passé.
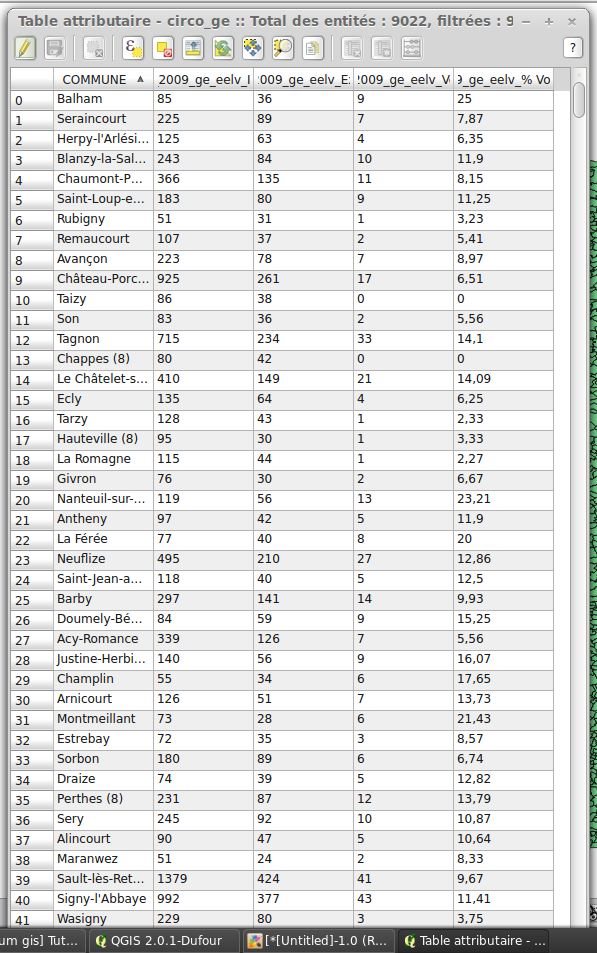
Cliquez sur l'image pour l'agrandir
¡ Vale ! Aucune encombre, on peut donc enregistrer cette couche .shp customisée en nouvelle couche .shp via > clic droit > Sauvegarder sous.
On choisit le format Esri Shapefile, et surtout on exporte le tout en UTF-8.
Transformer une colonne Texte en une colonne Nombre
Dernière joyeuseté, et non des moindres : après la jointure, le .shp contient des colonnes Texte là où il devrait y avoir des colonnes Nombre. On a beau être certains que les colonnes du .csv étaient bien formatées comme des nombres cela ne change rien.
Et un problème arrive vite : quand on trie les résultats, une valeur comme 9,25 se trouve supérieure à une valeur comme 63,47. Pas terrible... Heureusement, on peut facilement transformer sur QGis une colonne à partir d'une autre.
Pour cela, on bascule en mode Edition (icône de crayon) et > clic > Ouvrir la table des attributs. De là, on clique sur l'option Ouvrir la calculatrice de champ, en haut tout à droite.
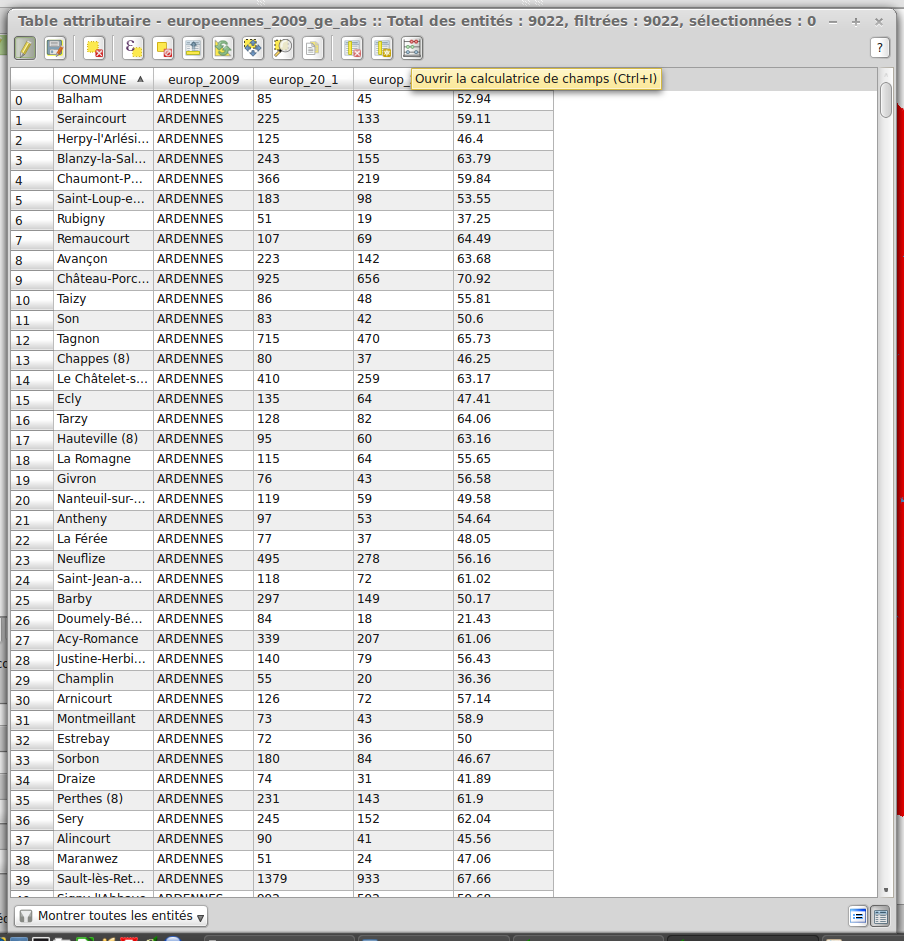
Cliquez sur l'image pour l'agrandir
De là, on peut créer une nouvelle colonne à partir d'une déjà présente.
Il suffit de choisir un format de colonne (rappel : un nombre avec décimales doit être formaté en real, pas en integer), de lui donner un nom et d'écrire une ligne de conversion, comme ci-après :

Cliquez sur l'image pour l'agrandir
Dans l'exemple, on va créer une colonne "Inscrits" en transformant en nombre entier les valeurs de la colonne europ_20_1. Une fois créée, on peut trier les valeurs de cette nouvelle colonne pour vérifier qu'elles sont (enfin) bien rangées !
Pour ma part, j'ai dû à chaque colonne créée, refermer et réouvrir ma couche .shp pour avoir effectivement des conversions en nombre sur les transformations suivantes. Ça ne doit être qu'un bug, mais je préfère le signaler.
Les limites techniques
Il y a forcément des limites dans le cas décrit précédemment. Voici celles que j'ai relevées :
- on peut fusionner des entités, mais pas obtenir les anciens tracés lorsqu'il y a eu fusion. Ainsi, si la commune A de 2013 est le résultat d'une fusion des communes B et C de 2004, il sera impossible de recréer ces tracés à partir de ceux fournis par OSM. Lorsque c'est arrivé, j'ai additionné les valeurs des deux communes sur celle de 2013.
- les fichiers impossibles à traiter en l'état. Petit coup de gueule sur ce fichier précis, fourni par data.gouv. Pour résumer simplement : aucune règle de nomenclature n'a été appliquée pour harmoniser les noms de communes, et chaque département a fait un peu comme il voulait. Certains toponymes sont donc en majuscules sans tirets, d'autres en majuscules avec tirets, d'autres écrits normales, certains "Les [...]" sont bien écrits, d'autre écrits "[...] (Les)". Bref, on dirait que quelqu'un a juste copié/collé les données de chaque département, sans se soucier de la réutilisation de l'ensemble. Vraiment pas glop...
A suivre
Ouf, ce fut dur, mais on est enfin arrivé à un fichier shapefile rempli de données réutilisables. Au menu pour la suite : comment transformer ce fichier en cartes choroplèthes affichant plus de 9 000 zones...
Edit
Jérémie a posté un commentaire plein de bon sens, et qui mérite un grand merci et qu'on s'attarde sur une autre méthode pour gagner encore plus de temps 🙂 !
Le fichier OSM contient en effet des identifiants uniques, dits codes INSEE, pour chaque commune (les deux chiffres du département plus les trois de l'identifiant local), mais le fichier de data.gouv les a séparés en deux.
Heureusement, en deux coups de cuillère à pot, on va pouvoir reconstituer ces id.
Text, pas Number
Tout d'abord, Calc Office va noter les chiffres 1, 2, 3, etc... Ce qui ne nous intéresse pas, puisqu'il nous faut trois chiffres sur chaque commune (001 pour la première, 010 sur la dixième et effectivement 100 sur la centième).
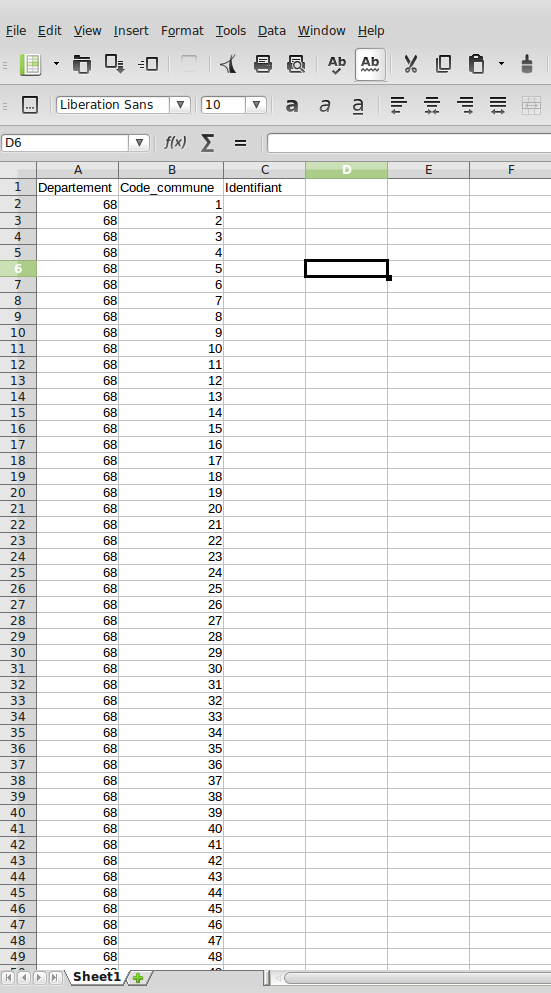
Cliquez pour agrandir l'image
Comment faire pour formater tout ça avec trois chiffres ? En convertissant simplement les colonnes en Texte, et pas en Nombre.
Pour cela, il suffit juste de cliquer-glisser sur les deux colonnes en haut (département et code commune) pour en sélectionner tout le contenu.
De là, un simple Ctrl+1 (pavé numérique) permet d'afficher les options de formatage de cellule. On choisit "Text", tout en bas.
On peut alors réécrire 1 en le précédant de deux 0, puis cliquer-glisser depuis le bord inférieur droit de la cellule jusqu'au 9, comme ceci :
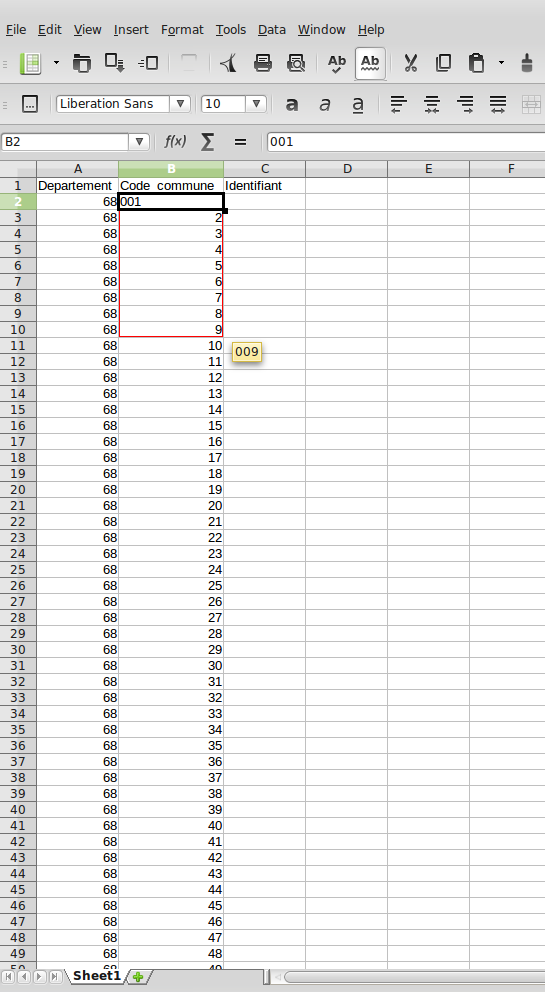
Cliquez sur l'image pour l'agrandir
Plus qu'à faire la même manip en faisant maintenant précéder 10 d'un seul zéro, et de faire la même glissade jusqu'à 99 :
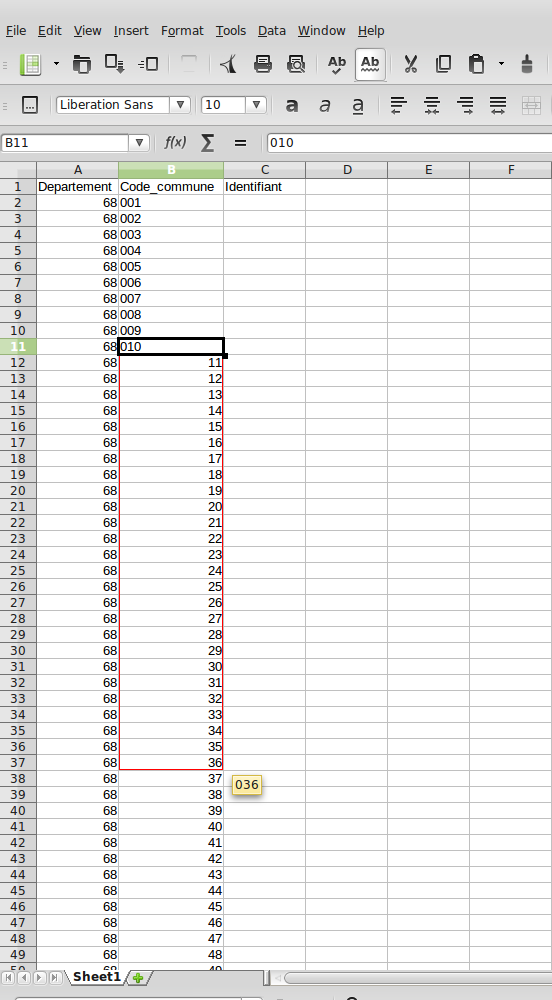
Cliquez sur l'image pour l'agrandir
Tous nos codes sont maintenant formatés avec trois chiffres, on n'a plus qu'à réunir le département et le code pour obtenir un identifiant unique.
Pour cela, on va dans la colonne qui va accueillir la fusion, et on tape à l'intérieur de la première cellule la formule =CONCATENATE(A1;B1)
Le résultat se plaque sur le bord gauche de la cellule, ce qui prouve qu'on se trouve bien face à un texte. Plus qu'à cliquer-glisser depuis le bord inférieur droit pour obtenir des identifiants identiques à ceux du fichier OSM.
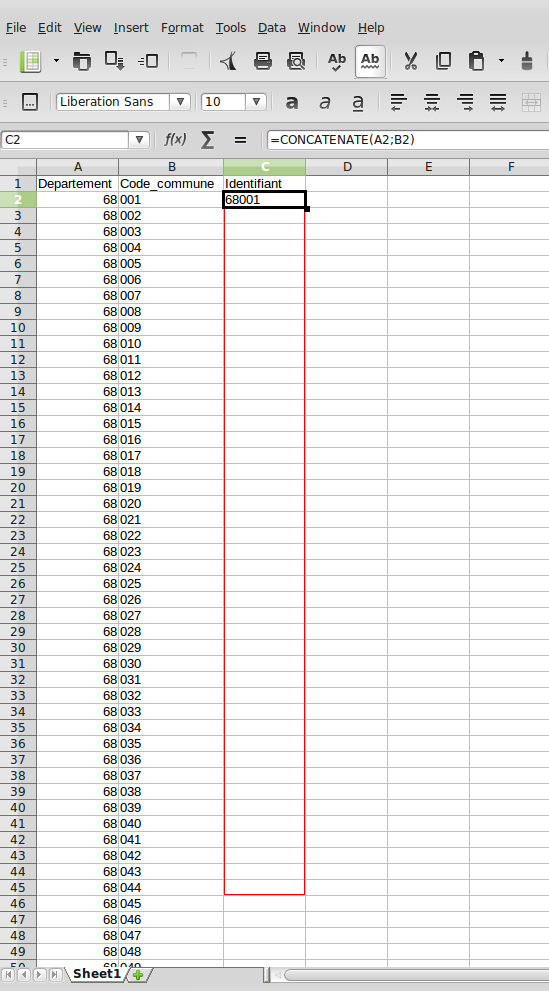
Cliquez sur l'image pour l'agrandir
Et si jamais on réalise dans QGis que la colonne identifiant de l'un des deux fichiers est un nombre au lieu d'un texte, l'astuce du calculateur de champs permettra de convertir tout ça rapido.
Cette astuce fait effectivement gagner beaucoup de temps, donc encore une fois un grand merci à Jérémie !
Gare à la suite logique !
Dans certains cas particuliers comme les fusions ou les "villages morts pour la France", la commune en question n'apparaît pas dans le fichier de data.gouv, et il peut donc y avoir un "trou" entre les codes.
Pour l'illustrer, prenons les communes A, B et C (respectivement les codes 1, 2 et 3) de 2013. Si en 2009, A était fusionnée à B, le code 2 n'apparaît pas dans le fichier.
Mais si vous êtes un peu distrait (ou à la bourre) et que vous effectuez l'astuce précédente du cliquer-glisser, le code qui suivra 001 sera 002, et non 003.
Bref, assurez-vous juste qu'il n'y ait aucun trou dans les codes de communes avant de vous lancer 🙂 !
Comments
Comment by Jérémie on 2014-02-09 22:27:16 +0100
Bonjour,
Quelque-uns de vos problèmes auraient été facilement réglés avec l'utilisation du code insee, code qui identifie de manière unique les communes françaises.
Ce code est présent de manière quasi-systématique dans toutes les données (dans la couche OSM). Par exemple, pour le fihcier excel que vous citez en fin d'article, la combinaison des colonnes code du département et code de la commune permet d'obtenir ce code insee (01001 pour la 1ere commune du fichier : ABERGEMENT CLEMENCIAT (L')).
Heureusement pour les géomaticiens, la question de l'identifiant unique est quand même la plupart du temps bien traitée !
Comment by Raphi on 2014-02-09 23:59:59 +0100
Salut Jérémie, et merci pour votre comm' ! J'y réponds de ce pas.
Vous partez du principe que les identifiants OSM sont les mêmes que ceux des fichiers, ce qui théoriquement rendrait votre solution effectivement optimale. Malheureusement, c'est faux et je vais me permettre de détailler.
Dans les Excel dont je me suis servi, les identifiants de communes ne sont pas uniques. La commune 1 de l'Ain sera identifiée 1, comme la commune 1 du Haut-Rhin.
On pourrait aisément contourner cela grâce à l'ordre alphabétique des communes. Comme ce tri est logique, en se plaçant dans la colonne des identifiants, on ajouterait simplement le code du département avant celui-ci et on cliquerait/glisserait sur le reste pour compléter la suite logique.
Effectivement rapide, sauf que l'on risquerait de zapper certaines communes particulières, comme Louvemont-Côte-du-Poivre.
Ce village, n°55307, existe administrativement et apparaît donc dans les fichiers OSM, en revanche il n'est pas peuplé et n'apparaît pas dans le fichier électoral de data.gouv.
Si je m'amuse alors à intuitivement imaginer que tous les identifiants des communes de la Meuse de ce fichier se suivent, je me retrouve avec un identifiant 55307 qui ne correspond pas à la bonne commune, et les résultats décalés vont rendre fausses bon nombre de villes du département...
La voie que j'ai choisie, certes très coûteuse en temps et de loin pas la plus optimale, m'a au moins permis d'éviter ce genre d'ennui...
Comment by Jérémie on 2014-02-10 10:37:29 +0100
Salut Raphi,
Je t'assure que le code INSEE est unique, à condition d'y incorporer le numéro de département.
Le code INSEE (en France métropolitaine) se construit en prenant le numéro de département sur 2 caractères (donc "01" pour l'Ain) et le code commune sur 3 caractères (001 pour la commune 1) ce qui donne un identifiant unique sur 5 caractères (6 pour les DOM).
Effectivement, çà correspond à l'ordre alphabétique de chaque département (du moins à la base. Forcément, les modifications qu'il y a eu depuis causent de multiples dérogations à cette règle).
Le code dans OSM est bien le code INSEE.
Et dans les fichiers que tu télécharges sur opendata, soit tu l'as dans une colonne unique soit séparé dans 2 colonnes (1 pour le département et une pour le code commune).
Ne le prends pas du tout pour toi, ton boulot est très intéressant.
Mais c'est une bonne illustration d'un problème générique de l'information (géographique ou non géographique) : avoir la donnée, c'est bien mais avoir la métadonnée (les informations décrivant précisément la donnée : échelle, cadre de création, date de validité, descriptions des champs...) avec c'est beaucoup mieux !
L'Open Data c'est génial !
Mais pour que ça soit le plus utile possible et que les citoyens puissent s'emparer des données, il ne faut surtout pas négliger la métadonnée qui devrait être systématiquement fournie avec la données elle-même.
Bref, c'est un axe d'effort pour tous les fournisseurs de données et qui n'est d'ailleurs pas du tout ignoré (notamment dans la directive européenne INSPIRE qui impulse la mise à disposition des données par les services publics).
Pour finir, j'invite tous les gens souhaitant traiter de la donnée géographique libre à ne pas hésiter à poser des questions sur les forums pro s'ils ont des doutes ou des interrogations. Il y a 2 forums très actifs de l'information géographique en France : forumSig et Georezo.
Comment by Raphi on 2014-02-10 10:48:40 +0100
J'ai bien compris Jérémie, et il n'y a aucun problème avec tes commentaires. Au contraire, je suis bien content que des spécialistes réagissent 😉 !
J'expose juste une limite que j'ai constatée empiriquement. La solution que tu proposes est évidemment la plus optimale au niveau du temps, mais elle n'empêche pas les possibles coquilles et erreurs que j'ai pu constater dans certains toponymes (certes ultra minoritaires, mais quand même).
De plus, même avec l'identifiant unique, je trouve que les nomenclatures différentes sur un même tableur sont une véritable aberration.
Merci encore en tout cas, et j'ai bien noté les adresses des forums !
Comment by Fabien on 2014-02-10 15:28:31 +0100
Bonjour,
En effet le code Insee est unique pour les communes françaises. Il est composé du code département (2 chiffres) et du code commune (3 chiffres).
Je dis chiffre, mais en fait c'est bien une chaîne de caractère. Par exemple la 1ere commune de l'Ain : 01001.
A l'import du CSV sur Excel il faut donc lui préciser le format de cellule "text" de ces 2 colonnes (code département, code commune)
Ensuite pour créer le code INSEE unique, il suffit de faire la formule =A1 & A2 pour concaténer le tout.
Pour le problème du typage des .csv systématiquement en chaîne de caractères, il existe des solution pour définir le type et donc ne pas fusionner la couche référentiel (.shp) et les données (.csv) .
La solution la plus simple et de créer un fichier .csvt (qui indique le typage) et portant le même nom que le csv .
Une application automatise cela :
http://dogeo.fr/index.php/applications/csvt4bruch-typer-un-csv-pour-qgis
En espérant que ces éléments puissent simplifier votre travail.
Comment by Raphi on 2014-02-11 13:06:24 +0100
Salut Fabien ! Merci, comme vous pouvez le voir la mise à jour avec la méthode pour avoir les id uniques a été effectuée dès le deuxième comm' de Jérémie.
Belle journée à vous, et à bientôt.